- 서버전문업체 아이티마야
- HPC서버
-
GPU서버
-
4GPU Server
-
8GPU Server
-
HGX Server
-
2GPU Workstation
-
4GPU Workstation
-
Compact AI
-
10GPU Server
-
- BigData서버
- 가상화/HCI
- 스토리지/파일서버
- WEB/WAS/DB
- 워크스테이션
-
MLOps/SW지원/유지보수
-
Cloud
-
Open Source
-
NVIDIA
-
HCI
-
Backup
-
MLOps
-
HW/SW 유지보수
-
AS
-
테크니컬 스토리
아이티마야의 새로운 기술 뉴스를 만나보세요.Horovod란?
등록일
2026.04.28
첨부파일
왜 분산 학습인가? 왜 Horovod 인가?
Horovod란?
Horovod는 Uber에서 오픈소스로 공개한 분산 딥러닝 학습 프레임워크이다.
쉽게 말해, 하나의 GPU로 학습시키기에 너무 오래 걸리는 거대한 인공지능 모델을 여러 개의 GPU 또는 여러 대의 서버에 나눠서 아주 빠르게 학습시킬 수 있도록 도와주는 도구
쉽게 말해, 하나의 GPU로 학습시키기에 너무 오래 걸리는 거대한 인공지능 모델을 여러 개의 GPU 또는 여러 대의 서버에 나눠서 아주 빠르게 학습시킬 수 있도록 도와주는 도구

- 왜 Horovod를 쓰나요?
- 기존의 분산 학습 방식(Parameter Server 방식)은 그래디언트를 주고받을 때 특정 서버에 병목 현상이 생기는 단점이 있었습니다. Horovod는 이를 해결하기 위해 Ring-Allreduce라는 알고리즘을 사용합니다.
- - 효율성 : GPU 개수를 늘리는 만큼 학습 속도가 거의 선형적으로 빨라집니다.
- - 간결함 : 기존 단일 GPU 용 코드에 몇 줄만 추가하면 바로 분산 학습이 가능합니다.
- - 범용성 : TensorFlow, PyTorch, Keras 등 주요 프레임워크를 모두 지원합니다.

[NVIDIA Pascal GPU 환경에서 두 가지 AI 모델(Inception V3, ResNet-101)을 돌렸을 때의 결과입니다.]
실무 기준
Horovod → HPC / 대규모 클러스터
DDP → 일반적인 GPU 서버
- 핵심 원리: Ring-Allreduce
- 모든 GPU가 원(Ring) 형태로 연결되어 데이터를 주고받는 방식입니다. 중앙 서버 없이 각 GPU가 옆에 있는 GPU와 데이터를 주고받으며 동기화하기 때문에 네트워크 부하가 균등하게 분산됩니다.
- - Parameter Server (기존 방식): 중앙 서버가 모든 GPU로부터 데이터를 받고 다시 보내줍니다. GPU가 많아질수록 중앙 서버의 네트워크 대역폭에 병목 현상이 발생하여 효율이 급격히 떨어집니다.
- - Ring-Allreduce (Horovod 방식): 모든 GPU가 고리(Ring) 형태로 연결됩니다. 각 GPU는 전체 데이터를 한꺼번에 보내는 대신, 데이터를 작은 조각으로 나누어 옆에 있는 GPU에게만 전달합니다.
- 주요 구성 요소
- Horovod를 사용할 때 반드시 이해해야 하는 4가지 용어입니다.
- 1.Size: 전체 프로세스(Worker)의 개수입니다. 보통 GPU의 총개수와 같습니다.
- 2.Rank: 각 프로세스에 부여된 고유 ID(0부터 Size-1까지)입니다.
- 3.Local Rank: 한 대의 서버(Node) 안에서의 프로세스 ID입니다. (예: 서버당 GPU가 4개라면 0, 1, 2, 3)
- 4.Allreduce: 모든 프로세스의 데이터를 통합(Sum/Average) 하여 다시 모든 프로세스에 동일하게 배포하는 연산입니다.
- Horovod의 소프트웨어 스택
- Horovod는 단순히 라이브러리 하나가 아니라, 고성능 통신을 위해 여러 하위 기술을 결합합니다.
- - MPI (Message Passing Interface): 프로세스 간의 통신 관리 및 실행을 담당합니다 (예: mpirun).
- - NCCL (NVIDIA Collective Communications Library): NVIDIA GPU 간의 통신을 최적화하는 라이브러리로, Horovod가 GPU 환경에서 매우 빠른 이유입니다.
- - Gloo: 페이스북에서 만든 통신 라이브러리로, GPU가 없는 환경이나 일반 CPU 환경에서 주로 사용됩니다.
장점
- 코드 수정 최소화
- - 기존 TensorFlow / PyTorch 코드에 몇 줄만 추가하면 분산 학습 가능
- 높은 성능
- - NVIDIA NCCL 기반 GPU 통신 최적화
- - Ring-AllReduce로 네트워크 효율 ↑
- 확장성 우수
- - 멀티 GPU / 멀티 노드 환경에서 안정적으로 확장 가능
- - HPC 클러스터에 적합
- 프레임워크 호환성
- - TensorFlow, PyTorch, Keras 모두 지원
단점
- 네트워크 의존성 높음
- - InfiniBand 같은 고속 네트워크 없으면 성능 저하
- 초기 구축 난이도
- - MPI, NCCL, 클러스터 환경 설정 필요
- 유연성 제한
- - AllReduce 방식만 사용 (Parameter Server 미지원)
- 디버깅 어려움
- - 분산 환경 특성상 문제 원인 파악이 까다로움
-
 이전글
이전글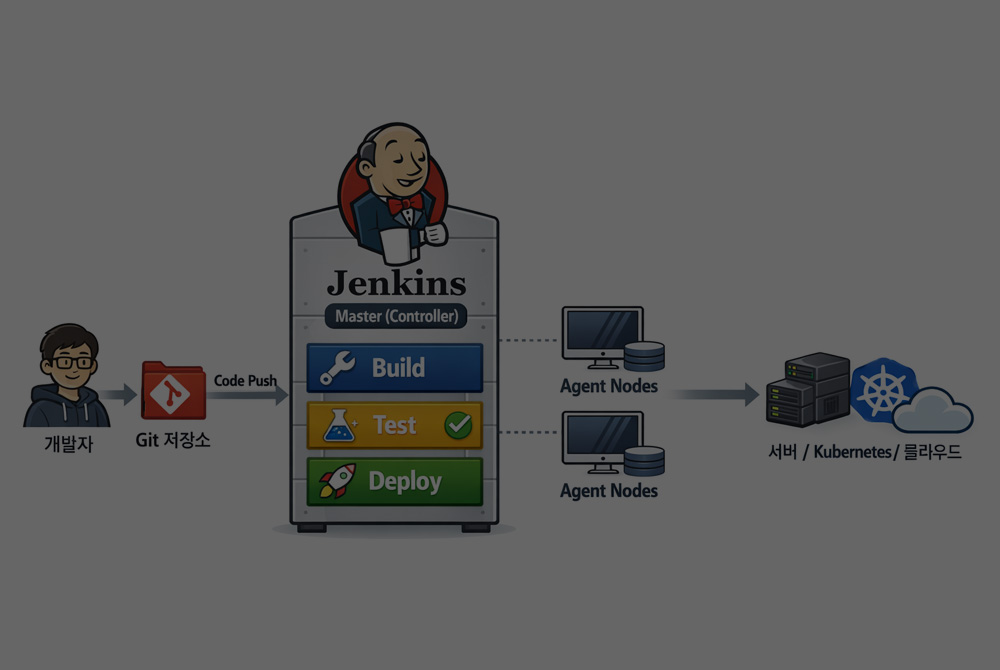 jenkins지속적으로 통합 및 배포를 위한 통합 서비스 제공 툴을 사용해 보자! jenkins 젠킨스는 소프트웨어 개발 시 지속적으로 통합 서비스를 제공/배포하는 툴입니다. 젠킨스를 사용하는 이유는 개발자들이 변경사항의 품질을 신속히 확인하고 문제를 발견할 수 있도록 돕기 때문입니다. 예를 들면 개발자 A와 B가 동시에 커밋 작업을 한다면 한 사람이 작업이 끝날 때까...2026.04.28
jenkins지속적으로 통합 및 배포를 위한 통합 서비스 제공 툴을 사용해 보자! jenkins 젠킨스는 소프트웨어 개발 시 지속적으로 통합 서비스를 제공/배포하는 툴입니다. 젠킨스를 사용하는 이유는 개발자들이 변경사항의 품질을 신속히 확인하고 문제를 발견할 수 있도록 돕기 때문입니다. 예를 들면 개발자 A와 B가 동시에 커밋 작업을 한다면 한 사람이 작업이 끝날 때까...2026.04.28 -
다음글
 보다 안정적으로 데이터를 보호하자!ZFS 파일시스템이란? 보다 안정적으로 데이터를 보호하자! 요즘 기업 환경에서 데이터는 저장물이 아니라 핵심 자산이 되었습니다. 데이터가 많아질수록 장애 한 번의 영향도 더 커지고, 복구 시간은 곧 비용이 됩니다. 특히 대용량 스토리지 환경에서는 RAID 만으로 디스크 장애는 막아도, 데이터 무결성과 빠른 복구까지 보장하긴 어렵습니다. 그래서 최근 스토리지...2026.01.14
보다 안정적으로 데이터를 보호하자!ZFS 파일시스템이란? 보다 안정적으로 데이터를 보호하자! 요즘 기업 환경에서 데이터는 저장물이 아니라 핵심 자산이 되었습니다. 데이터가 많아질수록 장애 한 번의 영향도 더 커지고, 복구 시간은 곧 비용이 됩니다. 특히 대용량 스토리지 환경에서는 RAID 만으로 디스크 장애는 막아도, 데이터 무결성과 빠른 복구까지 보장하긴 어렵습니다. 그래서 최근 스토리지...2026.01.14
PLEASE WAIT WHILE LOADING...